SyncUnsafeCell替换Mutex提高性能
1. 背景
在Rust开发过程中,很多情况下需要在不可变的情况下获取可变性或者在多线程的情况下可以安全的贡献可变数据。这种情况下我们一般使用**Mutex来实现通过加锁来实现。现在我们可以通过使用SyncUnsafeCell来替代Mutex**。
2. SyncUnsafeCell
SyncUnsafeCell 是 Rust 标准库中的一个类型,用于在多线程环境中安全地共享可变数据。它是 UnsafeCell 的一个包装,提供了额外的同步机制。
作用
- 共享可变数据:在 Rust 中,默认情况下,数据是不可变的,且不能在多个线程之间共享可变数据。
SyncUnsafeCell允许你在多线程环境中共享可变数据。 - 内部可变性:
SyncUnsafeCell提供了内部可变性,这意味着你可以在不获取可变引用的情况下修改其内容。这对于需要在多线程环境中共享可变状态的场景非常有用。 - 安全性:虽然名字中包含 "Unsafe",但
SyncUnsafeCell在多线程环境中提供了一定程度的安全性。它通过�内部的同步机制确保了对UnsafeCell的访问是安全的。
使用场景
- 多线程共享状态:当你需要在多个线程之间共享可变状态时,可以使用
SyncUnsafeCell。 - 性能优化:在某些情况下,使用
SyncUnsafeCell可以比使用Mutex或RwLock等同步原语更高效,因为它提供了更细粒度的控制。
3. SyncUnsafeCell在Rocketmq-rust中的应用
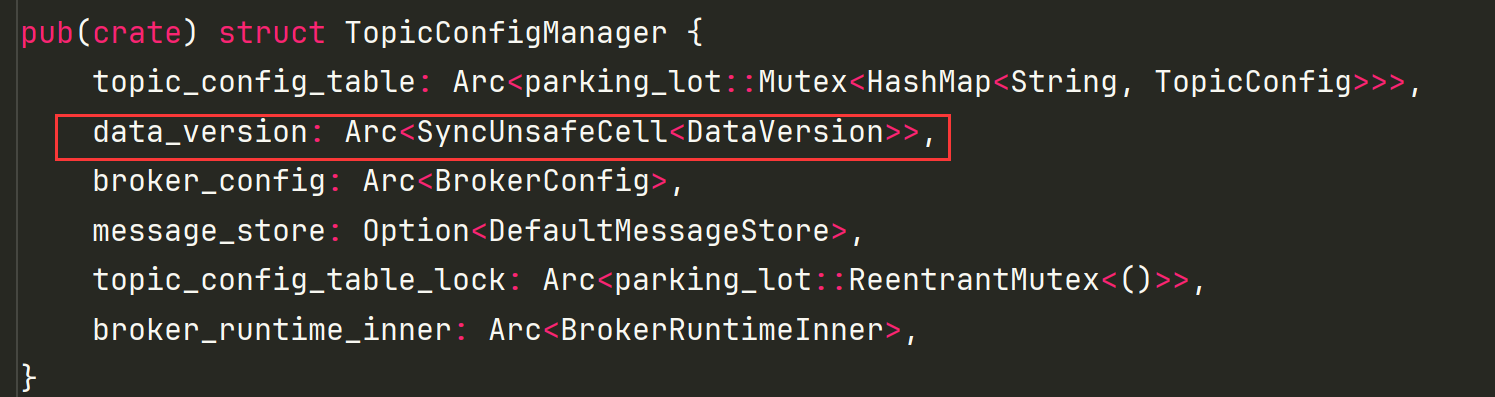
在**TopicConfigManager** 功能模块宗,因为很多方法都是使用了不可变引用 &self 那么需要修改**data_version** 就必须使用可变引用。为了解决这个问题就使用**Mutex** 来实现。如下图:

但是这种情况下每次获取可以变引用都需要进行加锁才能获取。而这里的同步性是可预见的。不存在数据竞争所以使用**SyncUnsafeCell来替换Mutex** 减少加锁带来的性能消耗。
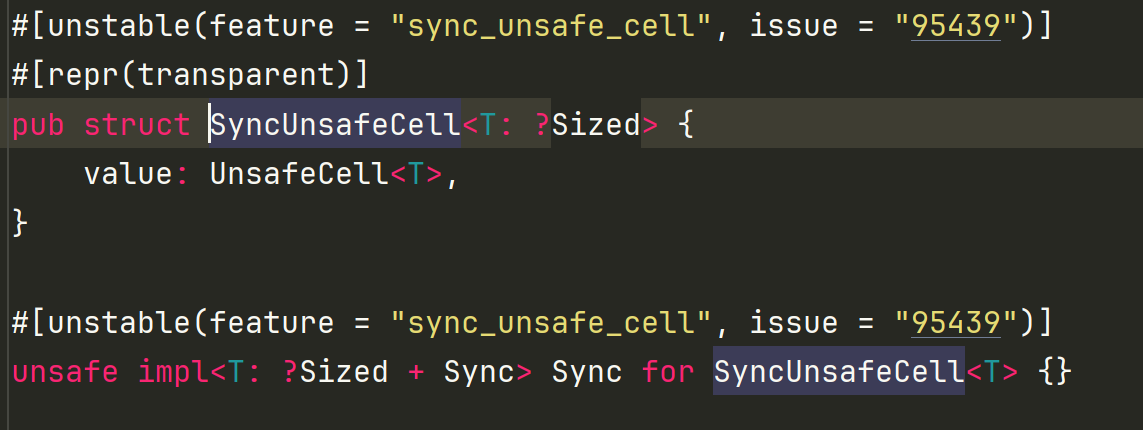
这里为什么不使用**UnsafeCell** 因为在rocketmq-rust项目中需要Sync也就是:
4.SyncUnsafeCell和Mutex的bench表现测试
我们使用下面的代码进行测试(测试代码参照:https://github.com/mxsm/rocketmq-rust/blob/main/rocketmq-broker/benches/syncunsafecell_mut.rs):
#![feature(sync_unsafe_cell)]
use std::cell::SyncUnsafeCell;
use std::collections::HashSet;
use criterion::criterion_group;
use criterion::criterion_main;
use criterion::Criterion;
pub struct Test {
pub a: SyncUnsafeCell<HashSet<String>>,
pub b: parking_lot::Mutex<HashSet<String>>,
}
impl Test {
pub fn new() -> Self {
Test {
a: SyncUnsafeCell::new(HashSet::new()),
b: parking_lot::Mutex::new(HashSet::new()),
}
}
pub fn insert_1(&self, key: String) {
unsafe {
let a = &mut *self.a.get();
a.insert(key);
}
}
pub fn insert_2(&self, key: String) {
let mut b = self.b.lock();
b.insert(key);
}
pub fn get_1(&self, key: &str) -> String {
unsafe {
let a = &*self.a.get();
a.get(key).unwrap().to_string()
}
}
pub fn get_2(&self, key: &str) -> String {
let b = self.b.lock();
b.get(key).unwrap().as_str().to_string()
}
}
fn benchmark_insert_1(c: &mut Criterion) {
let test = Test::new();
c.bench_function("insert_1", |b| {
b.iter(|| {
test.insert_1("key".to_string());
})
});
}
fn benchmark_insert_2(c: &mut Criterion) {
let test = Test::new();
c.bench_function("insert_2", |b| {
b.iter(|| {
test.insert_2("key".to_string());
})
});
}
fn benchmark_get_1(c: &mut Criterion) {
let test = Test::new();
let key = String::from("test_key");
// Insert key for the get benchmarks
test.insert_1(key.clone());
c.bench_function("get_1", |b| {
b.iter(|| {
test.get_1("test_key");
})
});
}
fn benchmark_get_2(c: &mut Criterion) {
let test = Test::new();
let key = String::from("test_key");
// Insert key for the get benchmarks
test.insert_2(key.clone());
c.bench_function("get_2", |b| {
b.iter(|| {
test.get_2("test_key");
})
});
}
criterion_group!(
benches,
benchmark_insert_1,
benchmark_insert_2,
benchmark_get_1,
benchmark_get_2
);
criterion_main!(benches);
测试命令:
cargo bench
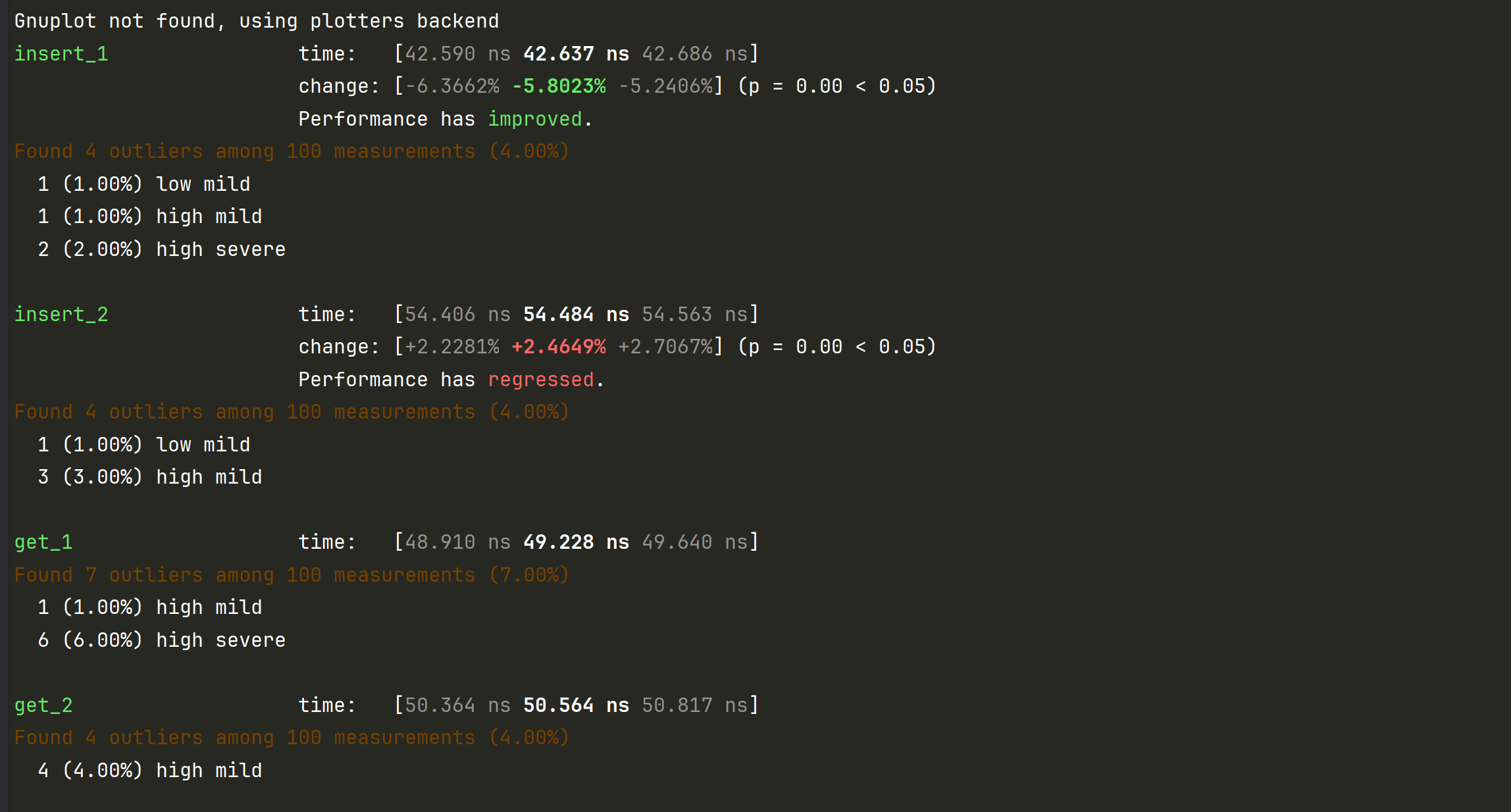
执行结果:
要比较 insert_1 和 insert_2 方法的优劣,我们需要考虑以下几个方面:
-
执行时间:
insert_1: 平均执行时间约为 42.637 ns。insert_2: 平均执行时间约为 54.484 ns。
从执行时间上看,
insert_1明显比insert_2快。 -
性能变化:
insert_1: 性能提升了约 5.8%。insert_2: 性能下降了约 2.5%。
insert_1的性能提升,而insert_2的性能下降。 -
异常值数量:
insert_1: 4个异常值,3个轻微异常,1个严重异常。insert_2: 4个异常值,均为轻微异常。
虽然两者的异常值数量相同,但
insert_1的异常值有一个严重异常,而insert_2的异常值均为轻微异常。
综合来看,insert_1 方法在执行时间和性能提升方面明显优于 insert_2,但需��要注意的是 insert_1 存在一个严重异常的情况。这表明在大多数情况下 insert_1 是更好的选择,但在某些极端情况下可能会有性能波动。
4.1 get_1 和 get_2 方法的比较
-
执行时间:
get_1: 平均执行时间约为 49.228 ns。get_2: 平均执行时间约为 50.564 ns。
从执行时间上看,
get_1稍微比get_2快。 -
异常值数量:
get_1: 7个异常值,1个轻微异常,6个严重异常。get_2: 4个异常值,均为轻微异常。
get_1存在较多的严重异常值,而get_2异常值较少且均为轻微异常。
结论
- 插入操作:
insert_1是更好的选择,因为它的执行时间更短且性能提升显著。虽然存在一些严重异常,但整体表现优于insert_2。 - 获取操作:
get_1的平均执行时间比get_2快,但存在较多严重异常。如果系统对性能一致性要求较高,get_2可能是更好的选择,因为它的异常值较少且均为轻微异常。
总的来说,如果追求平均性能且可以接受一定程度的性能波动,insert_1 和 get_1 是较好的选择;如果追求性能的一致性,insert_2 和 get_2 可能更适合。
让我们分析 insert_1 基准测试的结果:
4.2 图表分析
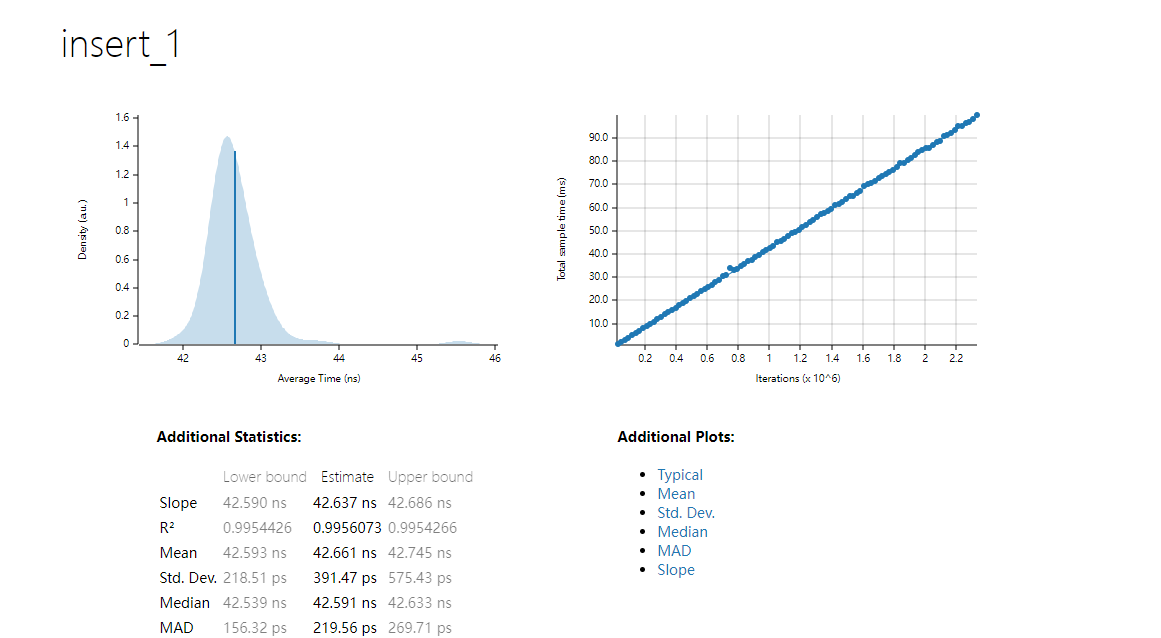
左侧图表(密度图)
- X轴:代表插入操作的平均时间(以纳秒为单位)。
- Y轴:代表密度(密度单位)。
- 蓝色区域:显示了每次迭代所花费时间的概率分布,密度图的高峰显示了最可能的时间范围。
- 蓝色垂直线:代表平均时间。对于
insert_1操作,平均时间大约为 42.637 ns。
右侧图表(总样本时间)
- X轴:表示迭代次数(以百万次为单位)。
- Y轴:表示总样本时间(以毫秒为单位)。
- 蓝色点:显示了总样本时间的线性回归,表明每次迭代的时间是相对恒定的。
附加统计数据
- Slope:斜率,估算的每次迭代所需时间。
- 下限:42.590 ns
- 估算值:42.637 ns
- 上限:42.686 ns
- R²:决定系数,表示数据拟合度。值越接近1,拟合度越高。
- R²:0.9954266
- Mean:平均时间。
- 42.661 ns
- Std. Dev.:标准差,表示数据的离散程度。
- 391.47 ps
- Median:中位数,表示数据的中间值。
- 42.591 ns
- MAD:中位绝对偏差,表示数据的波动性。
- 219.56 ps
结论
- 平均时间:
insert_1操作的平均时间为 42.637 ns。这表明操作的时间开销非常小。 - 一致性:高 R² 值(0.9954266)表明基准测试结果非常一致,操作时间非常稳定。
- 波动性:标准差(391.47 ps)和中位绝对偏差(219.56 ps)都非常小,表明操作时间波动很小。
总的来说,insert_1 操作性能非常稳定且高效,时间开销非常小。