Netty源码解析-池化内存管理解析
Netty版本:4.1.72.Final
Netty当下最热火最热门的网络编程框架需要处理海量的字节数据。Netty提供了字节池化的机制。对象池化内存分配,使用完成后归给内存次。池化内存,那么内存的管理必不可少。Netty基于jemalloc 实现了一套内存分配和管理的机制。
GitHub地址:https://github.com/jemalloc/jemalloc
4.1.72.Final 版本基于 jemalloc4 实现
借鉴 jemalloc 用来解决两个问题:
- 多线程下的内存回收与分配
- 内存的碎片化问题(不断分配和回收过程中会产生,jemalloc4 进一步优化了内存碎片产生)
1. Netty中内存的规格
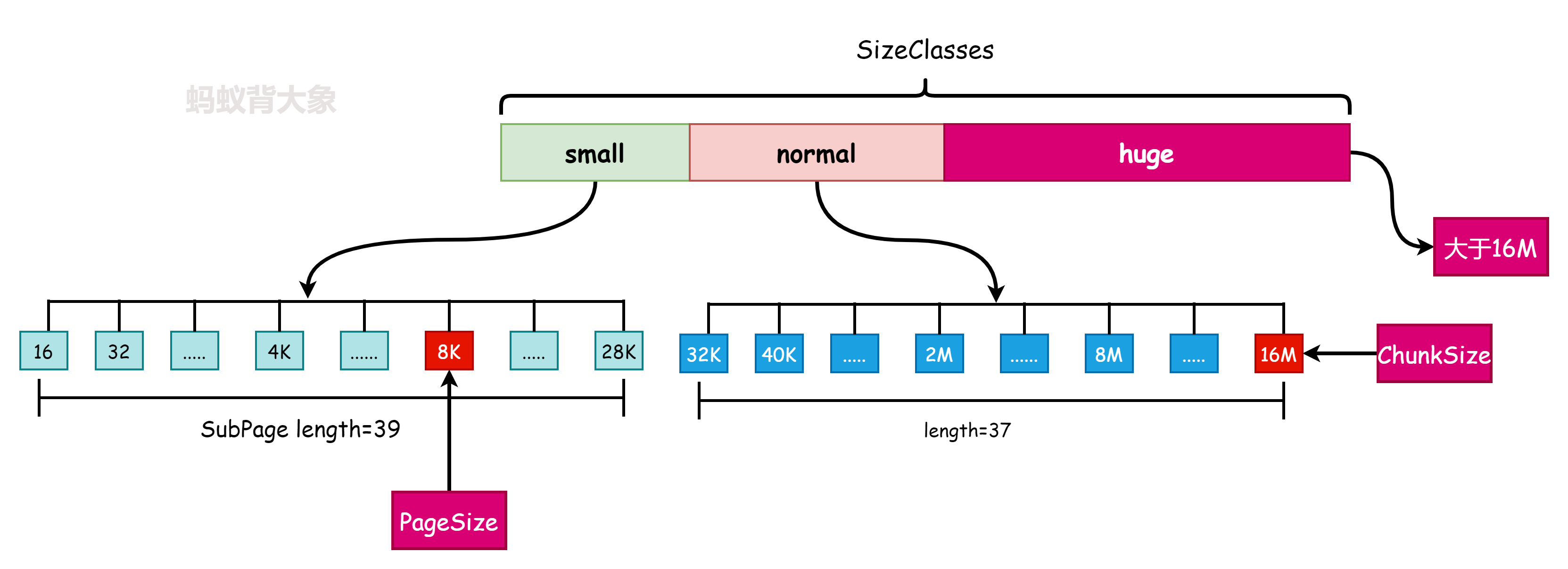
如上图所示Netty中内存规格分为三类(SizeClass中定义了):
enum SizeClass {
Small,
Normal
}
Tiny现在已经去掉
- small:0-28K(包含)
- normal: 28K(不包含)-16M(包含)
- Huge: 大于16M(不会进行池化)
Hotspot虚拟机的自动内存管理系统要求对象起始地址必须是8字节的整数倍,换句话说就是对象的大小必须是8字节的整数倍。而对象头部分正好是8字节的倍数(1倍或2倍),因此,当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。
Netty的内存管理实现借鉴了 jemalloc 所以很多概念和 jemalloc 中的概念相同。
- Chunk:Netty��向操作系统申请内存的最小单位(默认值16M),是Run的集合
- Run: 对应一块连续的内存,大小是Page的倍数
- Page: Chunk的最小分配单元,默认大小为8K,一个Chunk默认有2K个Page.
- Subpage: 负责Page内的内存分配,目的是为了减少内存的浪费。如果需要分配的内存小于Page的大小(8K)比如只有100B,如果直接分配一个Page(8K)那就直接浪费了。Subpage的最小是16B的倍数。Subpage没有固定的大小,需要根据用户分配的缓冲区决定。
2. Netty内存池的数据结构
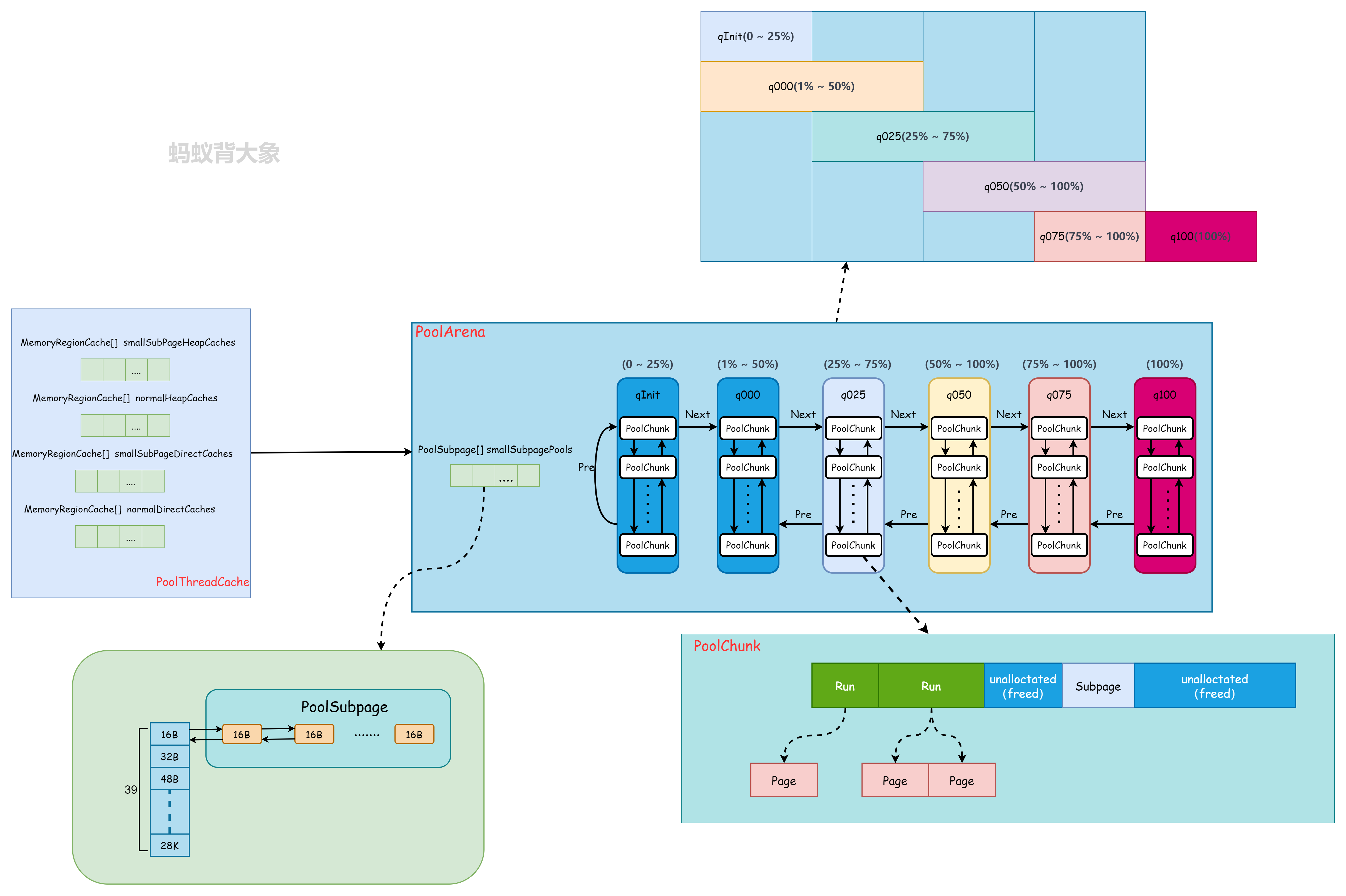
通过图可以知道,Netty根据内存模型抽象出来了一些组件, PoolArena、PoolChunk、PoolChunkList、PoolSubpage、PoolThreadCache、MemoryRegionCache 下面根据不同模块结合代码逐一分析其数据结构和实现。
Tips:很多概念和jemalloc中的概念相似大同小异,当前研究的代码版本中取消了网上很多资料里面出现的内存规格
tiny类型。只有 small、normal、huge, 具体是因为当前的版本的Netty内存分配实现是基于jemalloc4。
2.1 PoolSubpage数据结构解析
final class PoolSubpage<T> implements PoolSubpageMetric {
final PoolChunk<T> chunk; //所属的chunk
private final int pageShifts; //页面偏移量
private final int runOffset; //PoolSubpage 在 PoolChunk 中 memory 的偏移量
private final int runSize; //Run的大小
private final long[] bitmap; //每一块小内存状态
PoolSubpage<T> prev; //前一个PoolSubpage
PoolSubpage<T> next; //后一个PoolSubpage
boolean doNotDestroy;
int elemSize; // 每个小内存块的大小(最小16B)
private int maxNumElems; // 最多可以存放多少小内存块:8K(page默认大小)/elemSize=512
private int bitmapLength;
private int nextAvail;
private int numAvail; // 可用于分配的内存块个数
}
这里需要关注两个点:
- bitmap如何记录内存状态
- PoolSubpage如何和PoolArena关联
bitmap如何记录内存状态:
bitmap 数组长度由 PoolSubpage 的构造函数中的一段代码决定:
//LOG2_QUANTUM=4
bitmap = new long[runSize >>> 6 + LOG2_QUANTUM];
那么 runSize 的大小决定了 bitmap 的大小。 PoolChunk#allocateSubpage 分配 Run (Run的大小也是这里决定)
private long allocateSubpage(int sizeIdx) {
// Obtain the head of the PoolSubPage pool that is owned by the PoolArena and synchronize on it.
// This is need as we may add it back and so alter the linked-list structure.
PoolSubpage<T> head = arena.findSubpagePoolHead(sizeIdx);
synchronized (head) {
//allocate a new run
int runSize = calculateRunSize(sizeIdx);
//runSize must be multiples of pageSize
long runHandle = allocateRun(runSize);
if (runHandle < 0) {
return -1;
}
int runOffset = runOffset(runHandle);
assert subpages[runOffset] == null;
int elemSize = arena.sizeIdx2size(sizeIdx);
PoolSubpage<T> subpage = new PoolSubpage<T>(head, this, pageShifts, runOffset,
runSize(pageShifts, runHandle), elemSize);
subpages[runOffset] = subpage;
return subpage.allocate();
}
}
Tips: Run必须是PageSize的倍数。
PoolSubpage 通过位图 bitmap 记录子内存是否已经被使用,bit 的取值为 0 或者 1
.png)
PoolSubpage如何和PoolArena关联
在前面的图有体现, PoolArena 类中有一个 smallSubpagePools 属性。
abstract class PoolArena<T> extends SizeClasses implements PoolArenaMetric {
private final PoolSubpage<T>[] smallSubpagePools;
protected PoolArena(PooledByteBufAllocator parent, int pageSize,
int pageShifts, int chunkSize, int cacheAlignment) {
//省略部分代码
numSmallSubpagePools = nSubpages; // nsubpage = 39 查看之前的 《Netty源码解析-SizeClasses》文章中截图有
smallSubpagePools = newSubpagePoolArray(numSmallSubpagePools);
for (int i = 0; i < smallSubpagePools.length; i ++) {
smallSubpagePools[i] = newSubpagePoolHead();
}
//省略部分代码
}
private PoolSubpage<T> newSubpagePoolHead() {
PoolSubpage<T> head = new PoolSubpage<T>();
head.prev = head;
head.next = head;
return head;
}
}
.png)
Subpage有39个可以选择的类型。
2.2 PoolChunk数据结构解析
final class PoolChunk<T> implements PoolChunkMetric {
private static final int SIZE_BIT_LENGTH = 15;
private static final int INUSED_BIT_LENGTH = 1;
private static final int SUBPAGE_BIT_LENGTH = 1;
private static final int BITMAP_IDX_BIT_LENGTH = 32;
static final int IS_SUBPAGE_SHIFT = BITMAP_IDX_BIT_LENGTH;
static final int IS_USED_SHIFT = SUBPAGE_BIT_LENGTH + IS_SUBPAGE_SHIFT;
static final int SIZE_SHIFT = INUSED_BIT_LENGTH + IS_USED_SHIFT;
static final int RUN_OFFSET_SHIFT = SIZE_BIT_LENGTH + SIZE_SHIFT;
final PoolArena<T> arena; //所属的PoolArena
final Object base;
final T memory; // 存储的数据
final boolean unpooled; //是否池化
private final LongLongHashMap runsAvailMap; //管理PoolChunk的所有的Run(使用或者没有使用)
private final LongPriorityQueue[] runsAvail; // 优先队列,每一个队列管理同样大小的Run
private final PoolSubpage<T>[] subpages; //PoolSubpage列表
private final int pageSize;
private final int pageShifts;
private final int chunkSize;
private final Deque<ByteBuffer> cachedNioBuffers;
int freeBytes;
int pinnedBytes;
PoolChunkList<T> parent;
PoolChunk<T> prev; //前置节点
PoolChunk<T> next; //后置节点
//省略部分代码
}
Chunk内存中的结构如图:
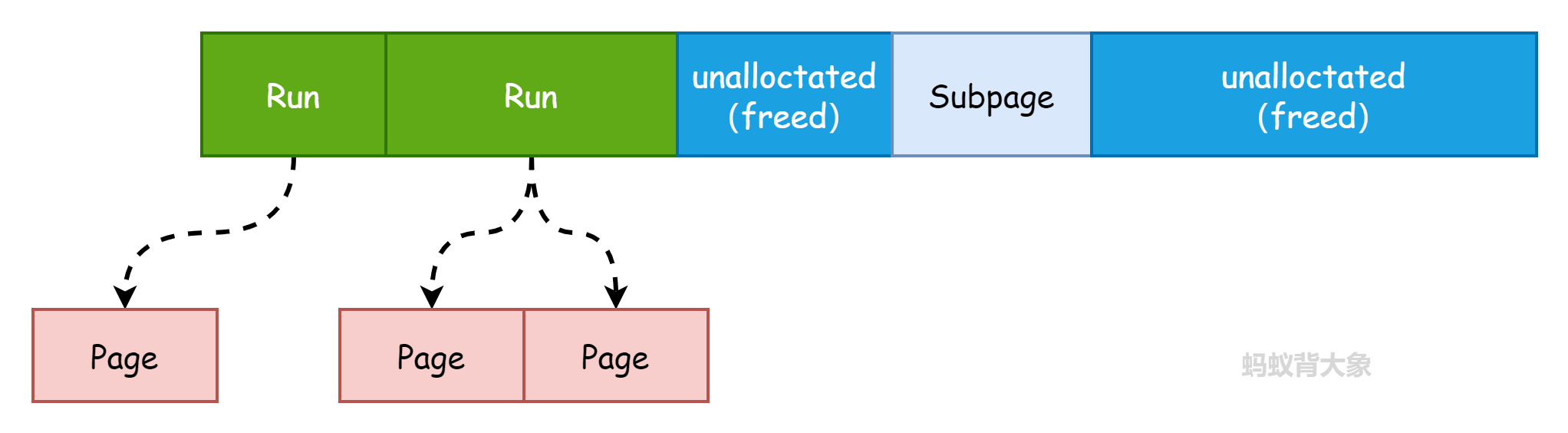
- Page组成Run,Run的大小必须是Page的整数倍 RunSize = N * PageSize (N >= 1的整数)
- Subpage的大小为 16B-28K,所以有时候Subpage也包含多个Page(这里是jemalloc4为��了进一步解决内存碎片化的问题)
- Chunk中还有一些没有使用的内存段。这些可以待分配
那么这些内存的状态以及大小什么的如何管理? 在Chunk中定义了一个 handle(long类型)
.png)
如上图,从上到下分别long的高位到低位。
- o(runOffset): runOffset(页面的在Chunk的偏移量),15bit
- s(size): Run的大小(这个字段存的是page的数量), 15bit
- u(isUsed): 当前内存是否使用标记位,1bit
- e(isSubpage): 当前是否为Subpage标记位,1bit
- b(bitmapIdx): Subpage的位图索引(bitmapIdx),如果为0表示不是Subpage,32bit
然后关注一下 PoolChunk 的几个重要属性:
-
runsAvailMap
管理Run状态的(使用,未使用)的map
key: runOffset
value: handle
-
runsAvail
一个优先队列数组,每一个队列管理相同大小的Runs。 Run按照offset进行存储,所以我们总是用较小的偏移量分配运行(优先队列的特点)
PoolChunk关键算法解析:
-
初始化
在一开始,我们存储了初始运行,也就是整个数据块,初始化的Run:
runOffset = 0
size = chunkSize
isUsed = false
isSubpage = false
bitmapIdx = 0 -
PoolChunk#allocateRun(int runSize)算法
private long allocateRun(int runSize) {
int pages = runSize >> pageShifts;
int pageIdx = arena.pages2pageIdx(pages);
synchronized (runsAvail) {
//find first queue which has at least one big enough run
int queueIdx = runFirstBestFit(pageIdx);
if (queueIdx == -1) {
return -1;
}
//get run with min offset in this queue
LongPriorityQueue queue = runsAvail[queueIdx];
long handle = queue.poll();
assert handle != LongPriorityQueue.NO_VALUE && !isUsed(handle) : "invalid handle: " + handle;
removeAvailRun(queue, handle);
if (handle != -1) {
handle = splitLargeRun(handle, pages);
}
int pinnedSize = runSize(pageShifts, handle);
freeBytes -= pinnedSize;
pinnedBytes += pinnedSize;
return handle;
}
}- 根据runSize找到第一个可用的Run在
runsAvail数组 - 如果Run的Page大于请求Page,则将其拆分,并且保存剩下的Run随后使用
- 根据runSize找到第一个可用的Run在
-
PoolChunk#allocateSubpage(int sizeIdx)算法
private long allocateSubpage(int sizeIdx) {
// Obtain the head of the PoolSubPage pool that is owned by the PoolArena and synchronize on it.
// This is need as we may add it back and so alter the linked-list structure.
PoolSubpage<T> head = arena.findSubpagePoolHead(sizeIdx);
synchronized (head) {
//allocate a new run
int runSize = calculateRunSize(sizeIdx);
//runSize must be multiples of pageSize
long runHandle = allocateRun(runSize);
if (runHandle < 0) {
return -1;
}
int runOffset = runOffset(runHandle);
assert subpages[runOffset] == null;
int elemSize = arena.sizeIdx2size(sizeIdx);
PoolSubpage<T> subpage = new PoolSubpage<T>(head, this, pageShifts, runOffset,
runSize(pageShifts, runHandle), elemSize);
subpages[runOffset] = subpage;
return subpage.allocate();
}
}- 根据sizeIdx找到一个没有满的Subpage。如果存在就返回,否则分配一个新的PoolSubpage,然后调用init()。注意:当调用init()这个subpage对象被添加到PoolArena的 subpagesPool 中。
- 调用
subpage.allocate()分配
-
PoolChunk#free(long handle, int normCapacity, ByteBuffer nioBuffer)算法
void free(long handle, int normCapacity, ByteBuffer nioBuffer) {
int runSize = runSize(pageShifts, handle);
pinnedBytes -= runSize;
if (isSubpage(handle)) {
int sizeIdx = arena.size2SizeIdx(normCapacity);
PoolSubpage<T> head = arena.findSubpagePoolHead(sizeIdx);
int sIdx = runOffset(handle);
PoolSubpage<T> subpage = subpages[sIdx];
assert subpage != null && subpage.doNotDestroy;
// Obtain the head of the PoolSubPage pool that is owned by the PoolArena and synchronize on it.
// This is need as we may add it back and so alter the linked-list structure.
synchronized (head) {
if (subpage.free(head, bitmapIdx(handle))) {
//the subpage is still used, do not free it
return;
}
assert !subpage.doNotDestroy;
// Null out slot in the array as it was freed and we should not use it anymore.
subpages[sIdx] = null;
}
}
//start free run
synchronized (runsAvail) {
// collapse continuous runs, successfully collapsed runs
// will be removed from runsAvail and runsAvailMap
long finalRun = collapseRuns(handle);
//set run as not used
finalRun &= ~(1L << IS_USED_SHIFT);
//if it is a subpage, set it to run
finalRun &= ~(1L << IS_SUBPAGE_SHIFT);
insertAvailRun(runOffset(finalRun), runPages(finalRun), finalRun);
freeBytes += runSize;
}
if (nioBuffer != null && cachedNioBuffers != null &&
cachedNioBuffers.size() < PooledByteBufAllocator.DEFAULT_MAX_CACHED_BYTEBUFFERS_PER_CHUNK) {
cachedNioBuffers.offer(nioBuffer);
}
}- 如果是Subpage,那么将分片返回到当前的Subpage.
- 如果Subpage没有被使用或者是一个Run,开启释放Run
- 合并连续可用的Run
- 保存合并的Run
2.3 PoolArena数据结构解析
abstract class PoolArena<T> extends SizeClasses implements PoolArenaMetric {
static final boolean HAS_UNSAFE = PlatformDependent.hasUnsafe();
enum SizeClass {
Small,
Normal
}
final PooledByteBufAllocator parent; //所属分配器
final int numSmallSubpagePools; // 39
final int directMemoryCacheAlignment;
private final PoolSubpage<T>[] smallSubpagePools;
private final PoolChunkList<T> q050;
private final PoolChunkList<T> q025;
private final PoolChunkList<T> q000;
private final PoolChunkList<T> qInit;
private final PoolChunkList<T> q075;
private final PoolChunkList<T> q100;
private final List<PoolChunkListMetric> chunkListMetrics;
// Metrics for allocations and deallocations
private long allocationsNormal;
// We need to use the LongCounter here as this is not guarded via synchronized block.
private final LongCounter allocationsSmall = PlatformDependent.newLongCounter();
private final LongCounter allocationsHuge = PlatformDependent.newLongCounter();
private final LongCounter activeBytesHuge = PlatformDependent.newLongCounter();
private long deallocationsSmall;
private long deallocationsNormal;
// We need to use the LongCounter here as this is not guarded via synchronized block.
private final LongCounter deallocationsHuge = PlatformDependent.newLongCounter();
// Number of thread caches backed by this arena.
final AtomicInteger numThreadCaches = new AtomicInteger();
//省略部分代码
}
Netty 借鉴了 jemalloc 中 Arena 的设计思想,采用固定数量的多个 Arena 进行内存分配,Arena 的默认数量通常是CPU核数*2(也可能选择内存计算关系较小的一个),通过创建多个 Arena 来缓解资源竞争问题,从而提高内存分配效率。线程在首次申请分配内存时,会通过 round-robin 的方式轮询 Arena 数组,选择一个固定的 Arena,在线程的生命周期内只与该 Arena 打交道,所以每个线程都保存了 Arena 信息,从而提高访问效率。下面代码就是计算PoolArena默认个数:
public class PooledByteBufAllocator extends AbstractByteBufAllocator implements ByteBufAllocatorMetricProvider {
private static final int DEFAULT_NUM_HEAP_ARENA; //默认arena的数量
private static final int DEFAULT_NUM_DIRECT_ARENA;//默认arena的数量
static{
final int defaultMinNumArena = NettyRuntime.availableProcessors() * 2;
final int defaultChunkSize = DEFAULT_PAGE_SIZE << DEFAULT_MAX_ORDER;
DEFAULT_NUM_HEAP_ARENA = Math.max(0,
SystemPropertyUtil.getInt(
"io.netty.allocator.numHeapArenas",
(int) Math.min(
defaultMinNumArena,
runtime.maxMemory() / defaultChunkSize / 2 / 3)));
DEFAULT_NUM_DIRECT_ARENA = Math.max(0,
SystemPropertyUtil.getInt(
"io.netty.allocator.numDirectArenas",
(int) Math.min(
defaultMinNumArena,
PlatformDependent.maxDirectMemory() / defaultChunkSize / 2 / 3)));
}
}
PoolArena 有两个实现分别对应堆内内存和堆外内存:
- DirectArena
- HeapArena
图示数据结构如图:
.png)
包含了一个 smallSubpagePools( PoolSubpage<T>[]) 和6个PoolChunkList<T> 。
- smallSubpagePools存放small Subpage类型的内存快
- 6个PoolChunkList 存放使用率不同的Chunk,构成一个双向循环链表
PoolArena 对应实现了 Subpage 和 Chunk 中的内存分配。 PoolSubpage 负责分配小于等于28K的内存,PoolChunkList 负责大于等于32K的内存。PoolSubpage 分配的内存情况有39种(为什么可以查看之前的《Netty源码解析-SizeClasses》)。
PoolChunkList 在 PoolArena 初始化了6个:
protected PoolArena(PooledByteBufAllocator parent, int pageSize,
int pageShifts, int chunkSize, int cacheAlignment) {
q100 = new PoolChunkList<T>(this, null, 100, Integer.MAX_VALUE, chunkSize);
q075 = new PoolChunkList<T>(this, q100, 75, 100, chunkSize);
q050 = new PoolChunkList<T>(this, q075, 50, 100, chunkSize);
q025 = new PoolChunkList<T>(this, q050, 25, 75, chunkSize);
q000 = new PoolChunkList<T>(this, q025, 1, 50, chunkSize);
qInit = new PoolChunkList<T>(this, q000, Integer.MIN_VALUE, 25, chunkSize);
q100.prevList(q075);
q075.prevList(q050);
q050.prevList(q025);
q025.prevList(q000);
q000.prevList(null);
qInit.prevList(qInit);
}
.png)
Chunk 内存使用率的变化,Netty 会重新检查内存的使用率并放入对应的 PoolChunkList,所以 PoolChunk 会在不同的 PoolChunkList 移动。
疑问1:qInit 和 q000 为什么需要设计成两个
qInit 用于存储初始分配的 PoolChunk,因为在第一次内存分配时,PoolChunkList 中并没有可用的 PoolChunk,所以需要新创建一个 PoolChunk 并添加到 qInit 列表中。qInit 中的 PoolChunk 即使内存被完全释放也不会被回收,避免 PoolChunk 的重复初始化工作。
�疑问2:在方法 PoolArena#allocateNormal 为什么首先判断的是 q050
private void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int sizeIdx, PoolThreadCache threadCache) {
if (q050.allocate(buf, reqCapacity, sizeIdx, threadCache) ||
q025.allocate(buf, reqCapacity, sizeIdx, threadCache) ||
q000.allocate(buf, reqCapacity, sizeIdx, threadCache) ||
qInit.allocate(buf, reqCapacity, sizeIdx, threadCache) ||
q075.allocate(buf, reqCapacity, sizeIdx, threadCache)) {
return;
}
// Add a new chunk.
PoolChunk<T> c = newChunk(pageSize, nPSizes, pageShifts, chunkSize);
boolean success = c.allocate(buf, reqCapacity, sizeIdx, threadCache);
assert success;
qInit.add(c);
}
分配的逻辑 q050 -----> q025 -----> q000 ----> qInit ----> q075。
网上解释:折中的选择,在频繁分配内存的场景下,如果从 q000 开始,会有大部分的 PoolChunk 面临频繁的创建和销毁,造成内存分配的性能降低。如果从 q050 开始,会使 PoolChunk 的使用率范围保持在中间水平,降低了 PoolChunk 被回收的概率,从而兼顾了性能。(没有看到官方的设计说明)
2.4 PoolChunkList数据结构解析
final class PoolChunkList<T> implements PoolChunkListMetric {
private static final Iterator<PoolChunkMetric> EMPTY_METRICS = Collections.<PoolChunkMetric>emptyList().iterator();
private final PoolArena<T> arena;
private final PoolChunkList<T> nextList;
private final int minUsage;
private final int maxUsage;
private final int maxCapacity;
private PoolChunk<T> head;
private final int freeMinThreshold;
private final int freeMaxThreshold;
// This is only update once when create the linked like list of PoolChunkList in PoolArena constructor.
private PoolChunkList<T> prevList;
}
从上面的数据结构可以看出来,PoolChunkList组成了一个双向循环列表。
上面就是池化内存分配过程中使用的类和相关的数据结构。但是在分配缓存的过程中还有一个缓存存在。下面来分析一下缓存。缓存主要涉及到两个类:
- PoolThreadCache
- MemoryRegionCache
3. 池化分配中的缓存
3.1 PoolThreadCache
final class PoolThreadCache {
private static final InternalLogger logger = InternalLoggerFactory.getInstance(PoolThreadCache.class);
private static final int INTEGER_SIZE_MINUS_ONE = Integer.SIZE - 1;
final PoolArena<byte[]> heapArena;
final PoolArena<ByteBuffer> directArena;
// Hold the caches for the different size classes, which are tiny, small and normal.
private final MemoryRegionCache<byte[]>[] smallSubPageHeapCaches;
private final MemoryRegionCache<ByteBuffer>[] smallSubPageDirectCaches;
private final MemoryRegionCache<byte[]>[] normalHeapCaches;
private final MemoryRegionCache<ByteBuffer>[] normalDirectCaches;
private final int freeSweepAllocationThreshold;
private final AtomicBoolean freed = new AtomicBoolean();
private int allocations;
}
Netty官方的说明:充当分配的线程缓存。这个和jemalloc可伸缩内存分配技术一样。
当内存释放时,与 jemalloc 一样,Netty 并没有将缓存归还给 PoolChunk,而是使用 PoolThreadCache 缓存起来,当下次有同样规格的内存分配时,直接从 PoolThreadCache 取出使用即可。这个可在 PoolArena#tcacheAllocateSmall 方法可以看出来:
private void tcacheAllocateSmall(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity,
final int sizeIdx) {
if (cache.allocateSmall(this, buf, reqCapacity, sizeIdx)) {
// was able to allocate out of the cache so move on
return;
}
//省略部分代码
}
在PoolThreadCache缓存的时候使用了 MemoryRegionCache 。 存在两个纬度:
- 堆内或者堆外
- small或者normal
3.2 MemoryRegionCache
private abstract static class MemoryRegionCache<T> {
private final int size;
private final Queue<Entry<T>> queue;
private final SizeClass sizeClass;
private int allocations;
//省略部分代码
MemoryRegionCache(int size, SizeClass sizeClass) {
this.size = MathUtil.safeFindNextPositivePowerOfTwo(size);
queue = PlatformDependent.newFixedMpscQueue(this.size);
this.sizeClass = sizeClass;
}
}
这里有几个属性:
- size: 队列长度, small默认值为256, Normal的默认值为64
缓存最大数据大小为32K(PooledByteBufAllocator的静态变量DEFAULT_MAX_CACHED_BUFFER_CAPACITY设置了)
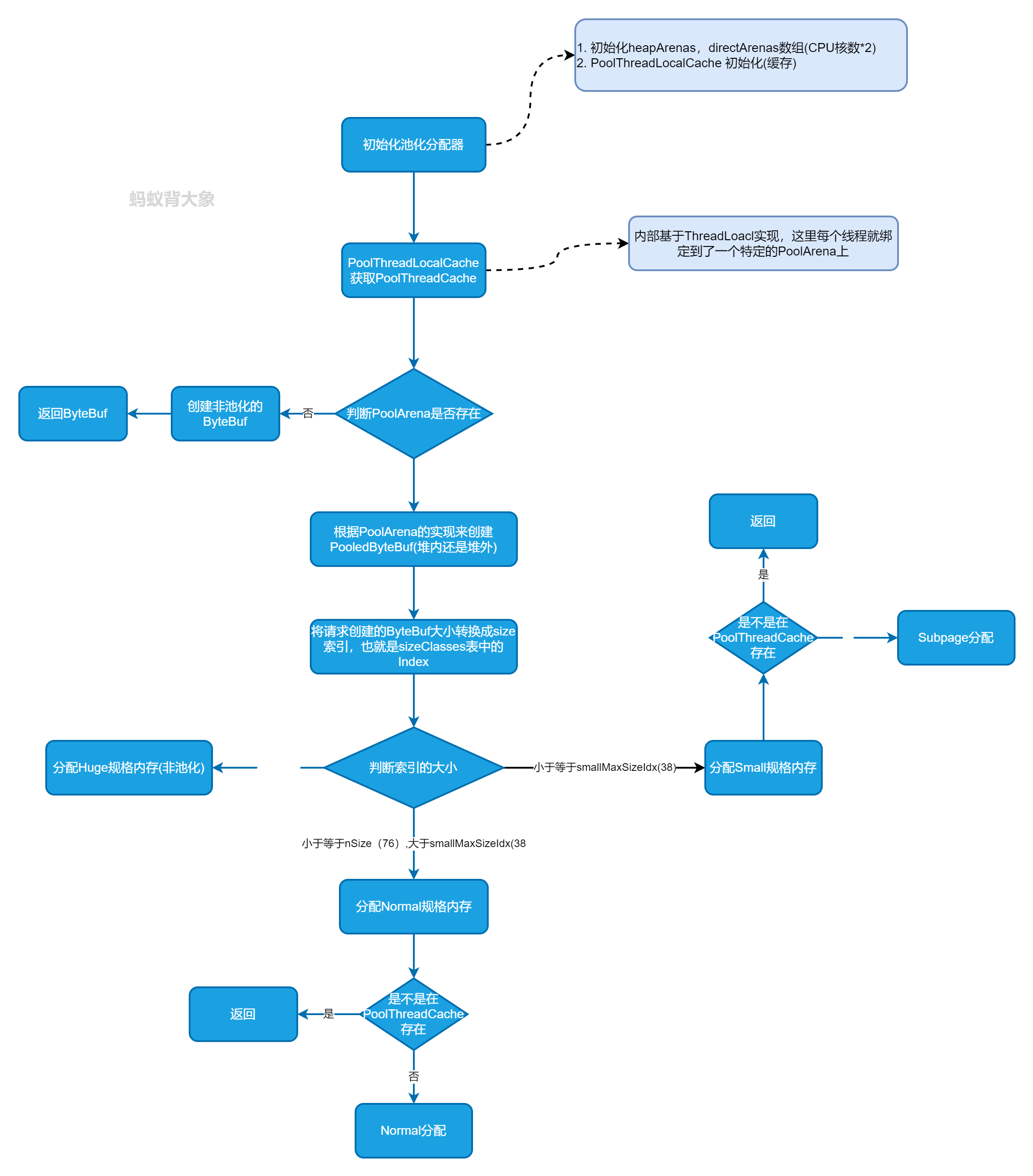
4. Netty 池化内存分配流程
Netty 池化 ByteBuf 分配由 PooledByteBufAllocator 来分配。分配流程如下:
5. 总结
- Netty内存分配现在是基于jemalloc4实现的,数据结构模型和之前的有所区别,特别是Chunk的分配管理上面
- Page, Subpage, PoolSubpage, PoolChunk、ChunkList、Run, PoolArena等相关类是实现池化内存分配的重要组成
- **
PooledByteBufAllocator**继承了分配的顶层接口ByteBufAllocator来作为分配堆内和堆外池化内存的入口 PoolThreadLocalCache负责缓存分配的内存,Small 的缓存队列默认长度为256,Normal的缓存队列默认长度为64,默认的最大缓存大小32K。